Supervised Learning: The Foundation of Predictive Modeling
Image by Author
Editor’s note: This article is a part of our series on visualizing the foundations of machine learning.
Welcome to the latest entry in our series on visualizing the foundations of machine learning. In this series, we will aim to break down important and often complex technical concepts into intuitive, visual guides to help you master the core principles of the field. This entry focuses on supervised learning, the foundation of predictive modeling.
The Foundation of Predictive Modeling
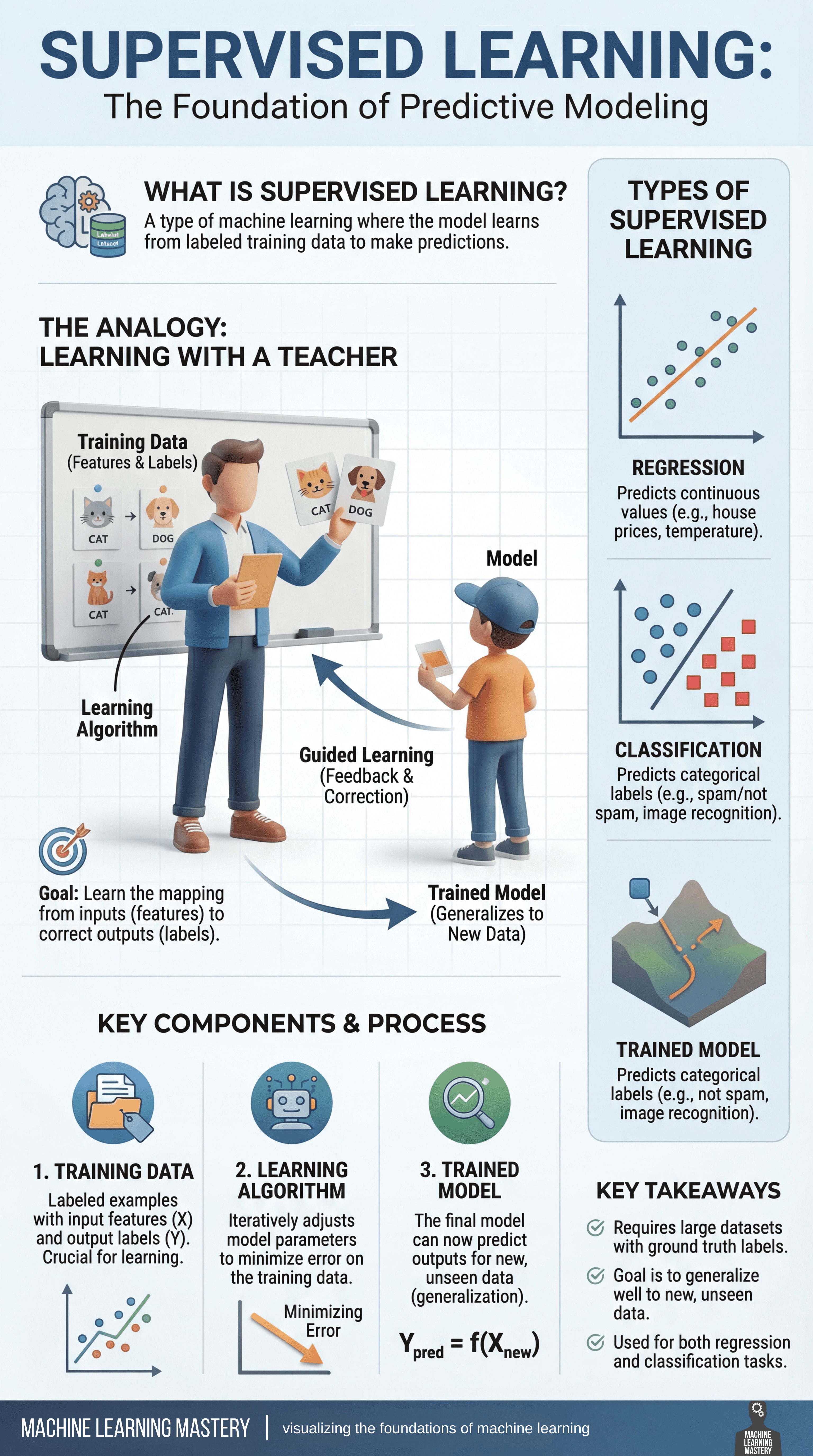
Supervised learning is widely regarded as the foundation of predictive modeling in machine learning. But why?
At its core, it is a learning paradigm in which a model is trained on labeled data — examples where both the input features and the correct outputs (ground truth) are known. By learning from these labeled examples, the model can make accurate predictions on new, unseen data.
A helpful way to understand supervised learning is through the analogy of learning with a teacher. During training, the model is shown examples along with the correct answers, much like a student receiving guidance and correction from an instructor. Each prediction the model makes is compared to the ground truth label, feedback is provided, and adjustments are made to reduce future mistakes. Over time, this guided process helps the model internalize the relationship between inputs and outputs.
The objective of supervised learning is to learn a reliable mapping from features to labels. This process revolves around three essential components:
- First is the training data, which consists of labeled examples and serves as the foundation for learning
- Second is the learning algorithm, which iteratively adjusts model parameters to minimize prediction error on the training data
- Finally, the trained model emerges from this process, capable of generalizing what it has learned to make predictions on new data
Supervised learning problems generally fall into two major categories: Regression tasks focus on predicting continuous values, such as house prices or temperature readings; Classification tasks, on the other hand, involve predicting discrete categories, such as identifying spam versus non-spam emails or recognizing objects in images. Despite their differences, both rely on the same core principle of learning from labeled examples.
Supervised learning plays a central role in many real-world machine learning applications. It typically requires large, high-quality datasets with reliable ground truth labels, and its success depends on how well the trained model can generalize beyond the data it was trained on. When applied effectively, supervised learning enables machines to make accurate, actionable predictions across a wide range of domains.
The visualization below provides a concise summary of this information for quick reference. You can download a PDF of the infographic in high resolution here.
Supervised Learning: Visualizing the Foundations of Machine Learning (click to enlarge)
Image by Author
Machine Learning Mastery Resources
These are some selected resources for learning more about supervised learning:
- Supervised and Unsupervised Machine Learning Algorithms – This beginner-level article explains the differences between supervised, unsupervised, and semi-supervised learning, outlining how labeled and unlabeled data are used and highlighting common algorithms for each approach.
Key takeaway: Knowing when to use labeled versus unlabeled data is fundamental to choosing the right learning paradigm. - Simple Linear Regression Tutorial for Machine Learning – This practical, beginner-friendly tutorial introduces simple linear regression, explaining how a straight-line model is used to describe and predict the relationship between a single input variable and a numerical output.
Key takeaway: Simple linear regression models relationships using a line defined by learned coefficients. - Linear Regression for Machine Learning – This introductory article provides a broader overview of linear regression, covering how the algorithm works, key assumptions, and how it is applied in real-world machine learning workflows.
Key takeaway: Linear regression serves as a core baseline algorithm for numerical prediction tasks. - 4 Types of Classification Tasks in Machine Learning – This article explains the four primary types of classification problems — binary, multi-class, multi-label, and imbalanced classification — using clear explanations and practical examples.
Key takeaway: Correctly identifying the type of classification problem guides model selection and evaluation strategy. - One-vs-Rest and One-vs-One for Multi-Class Classification – This practical tutorial explains how binary classifiers can be extended to multi-class problems using One-vs-Rest and One-vs-One strategies, with guidance on when to use each.
Key takeaway: Multi-class problems can be solved by decomposing them into multiple binary classification tasks.
Be on the lookout for for additional entries in our series on visualizing the foundations of machine learning.
About Matthew Mayo
Matthew Mayo (@mattmayo13) holds a master’s degree in computer science and a graduate diploma in data mining. As managing editor of KDnuggets & Statology, and contributing editor at Machine Learning Mastery, Matthew aims to make complex data science concepts accessible. His professional interests include natural language processing, language models, machine learning algorithms, and exploring emerging AI. He is driven by a mission to democratize knowledge in the data science community. Matthew has been coding since he was 6 years old.