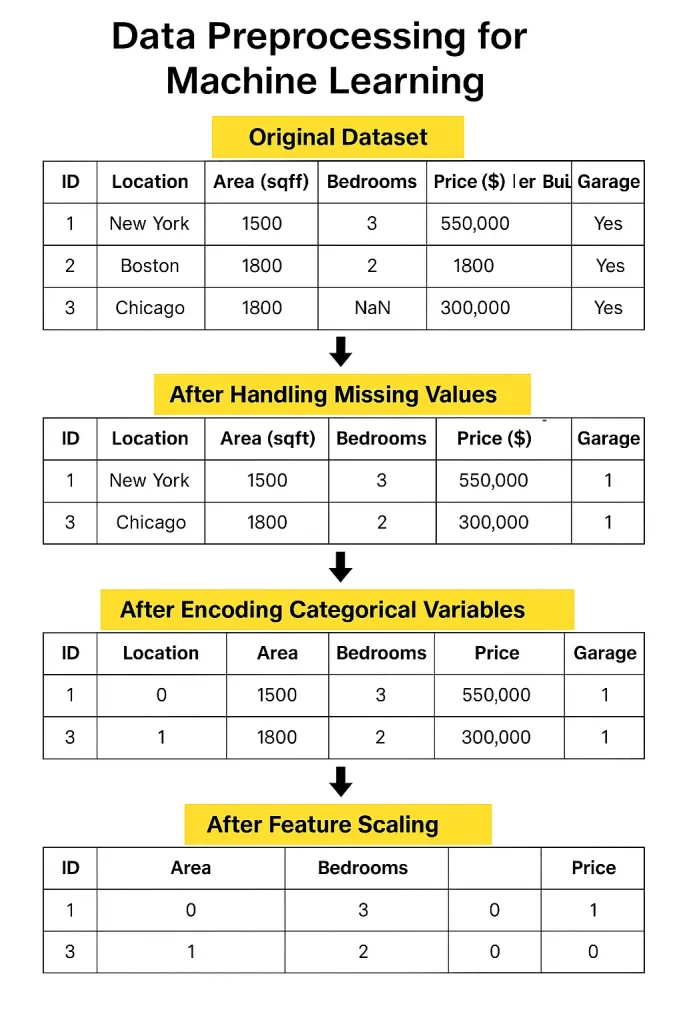
Data preprocessing removes errors, fills missing information, and standardizes data to help algorithms find actual patterns instead of being confused by either noise or inconsistencies.
Any algorithm needs properly cleaned up data arranged in structured formats before learning from the data. The machine learning process requires data preprocessing as its fundamental step to guarantee models maintain their accuracy and operational effectiveness while ensuring dependability.
The quality of preprocessing work transforms basic data collections into important insights alongside dependable results for all machine learning initiatives. This article walks you through the key steps of data preprocessing for machine learning, from cleaning and transforming data to real-world tools, challenges, and tips to boost model performance.
Understanding Raw Data
Raw data is the starting point for any machine learning project, and the knowledge of its nature is fundamental.
The process of dealing with raw data may be uneven sometimes. It often comes with noise, irrelevant or misleading entries that can skew results.
Missing values are another problem, especially when sensors fail or inputs are skipped. Inconsistent formats also show up often: date fields may use different styles, or categorical data might be entered in various ways (e.g., “Yes,” “Y,” “1”).
Recognizing and addressing these issues is essential before feeding the data into any machine learning algorithm. Clean input leads to smarter output.
Data Preprocessing in Data Mining vs Machine Learning

While both data mining and machine learning rely on preprocessing to prepare data for analysis, their goals and processes differ.
In data mining, preprocessing focuses on making large, unstructured datasets usable for pattern discovery and summarization. This includes cleaning, integration, and transformation, and formatting data for querying, clustering, or association rule mining, tasks that don’t always require model training.
Unlike machine learning, where preprocessing often centers on improving model accuracy and reducing overfitting, data mining aims for interpretability and descriptive insights. Feature engineering is less about prediction and more about finding meaningful trends.
Additionally, data mining workflows may include discretization and binning more frequently, particularly for categorizing continuous variables. While ML preprocessing may stop once the training dataset is prepared, data mining may loop back into iterative exploration.
Thus, the preprocessing goals: insight extraction versus predictive performance, set the tone for how the data is shaped in each field. Unlike machine learning, where preprocessing often centers on improving model accuracy and reducing overfitting, data mining aims for interpretability and descriptive insights.
Feature engineering is less about prediction and more about finding meaningful trends.
Additionally, data mining workflows may include discretization and binning more frequently, particularly for categorizing continuous variables. While ML preprocessing may stop once the training dataset is prepared, data mining may loop back into iterative exploration.
Core Steps in Data Preprocessing
1. Data Cleaning
Real-world data often comes with missing values, blanks in your spreadsheet that need to be filled or carefully removed.
Then there are duplicates, which can unfairly weight your results. And don’t forget outliers- extreme values that can pull your model in the wrong direction if left unchecked.
These can throw off your model, so you may need to cap, transform, or exclude them.
2. Data Transformation
Once the data is cleaned, you need to format it. If your numbers vary wildly in range, normalization or standardization helps scale them consistently.
Categorical data- like country names or product types- needs to be converted into numbers through encoding.
And for some datasets, it helps to group similar values into bins to reduce noise and highlight patterns.
3. Data Integration
Often, your data will come from different places- files, databases, or online tools. Merging all of it can be tricky, especially if the same piece of information looks different in each source.
Schema conflicts, where the same column has different names or formats, are common and need careful resolution.
4. Data Reduction
Big data can overwhelm models and increase processing time. By selecting only the most useful features or reducing dimensions using techniques like PCA or sampling makes your model faster and often more accurate.
Tools and Libraries for Preprocessing
- Scikit-learn is excellent for most basic preprocessing tasks. It has built-in functions to fill missing values, scale features, encode categories, and select essential features. It’s a solid, beginner-friendly library with everything you need to start.
- Pandas is another essential library. It’s incredibly helpful for exploring and manipulating data.
- TensorFlow Data Validation can be helpful if you’re working with large-scale projects. It checks for data issues and ensures your input follows the correct structure, something that’s easy to overlook.
- DVC (Data Version Control) is great when your project grows. It keeps track of the different versions of your data and preprocessing steps so you don’t lose your work or mess things up during collaboration.
Common Challenges
One of the biggest challenges today is managing large-scale data. When you have millions of rows from different sources daily, organizing and cleaning them all becomes a serious task.
Tackling these challenges requires good tools, solid planning, and constant monitoring.
Another significant issue is automating preprocessing pipelines. In theory, it sounds great; just set up a flow to clean and prepare your data automatically.
But in reality, datasets vary, and rules that work for one might break down for another. You still need a human eye to check edge cases and make judgment calls. Automation helps, but it’s not always plug-and-play.
Even if you start with clean data, things change, formats shift, sources update, and errors sneak in. Without regular checks, your once-perfect data can slowly fall apart, leading to unreliable insights and poor model performance.
Best Practices
Here are a few best practices that can make a huge difference in your model’s success. Let’s break them down and examine how they play out in real-world situations.
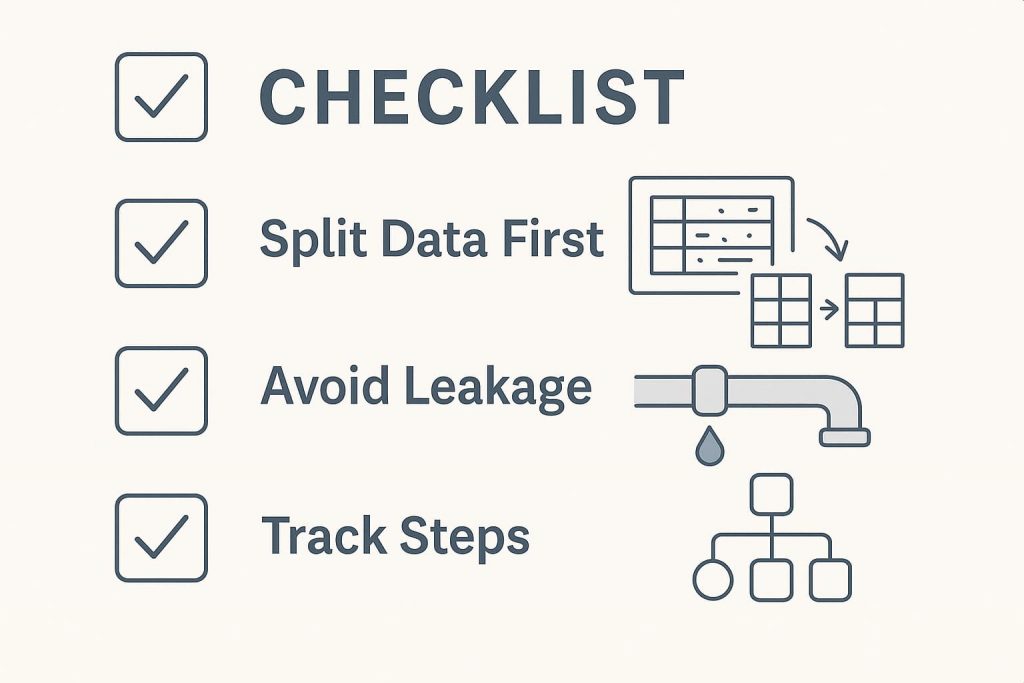
1. Start With a Proper Data Split
A mistake many beginners make is doing all the preprocessing on the full dataset before splitting it into training and test sets. But this approach can accidentally introduce bias.
For example, if you scale or normalize the entire dataset before the split, information from the test set may bleed into the training process, which is called data leakage.
Always split your data first, then apply preprocessing only on the training set. Later, transform the test set using the same parameters (like mean and standard deviation). This keeps things fair and ensures your evaluation is honest.
2. Avoiding Data Leakage
Data leakage is sneaky and one of the fastest ways to ruin a machine learning model. It happens when the model learns something it wouldn’t have access to in a real-world situation—cheating.
Common causes include using target labels in feature engineering or letting future data influence current predictions. The key is to always think about what information your model would realistically have at prediction time and keep it limited to that.
3. Track Every Step
As you move through your preprocessing pipeline, handling missing values, encoding variables, scaling features, and keeping track of your actions are essential not just for your own memory but also for reproducibility.
Documenting every step ensures others (or future you) can retrace your path. Tools like DVC (Data Version Control) or a simple Jupyter notebook with clear annotations can make this easier. This kind of tracking also helps when your model performs unexpectedly—you can go back and figure out what went wrong.
Real-World Examples
To see how much of a difference preprocessing makes, consider a case study involving customer churn prediction at a telecom company. Initially, their raw dataset included missing values, inconsistent formats, and redundant features. The first model trained on this messy data barely reached 65% accuracy.
After applying proper preprocessing, imputing missing values, encoding categorical variables, normalizing numerical features, and removing irrelevant columns, the accuracy shot up to over 80%. The transformation wasn’t in the algorithm but in the data quality.
Another great example comes from healthcare. A team working on predicting heart disease
used a public dataset that included mixed data types and missing fields.
They applied binning to age groups, handled outliers using RobustScaler, and one-hot encoded several categorical variables. After preprocessing, the model’s accuracy improved from 72% to 87%, proving that how you prepare your data often matters more than which algorithm you choose.
In short, preprocessing is the foundation of any machine learning project. Follow best practices, keep things transparent, and don’t underestimate its impact. When done right, it can take your model from average to exceptional.
Frequently Asked Questions (FAQ’s)
1. Is preprocessing different for deep learning?
Yes, but only slightly. Deep learning still needs clean data, just fewer manual features.
2. How much preprocessing is too much?
If it removes meaningful patterns or hurts model accuracy, you’ve likely overdone it.
3. Can preprocessing be skipped with enough data?
No. More data helps, but poor-quality input still leads to poor results.
3. Do all models need the same preprocessing?
No. Each algorithm has different sensitivities. What works for one may not suit another.
4. Is normalization always necessary?
Mostly, yes. Especially for distance-based algorithms like KNN or SVMs.
5. Can you automate preprocessing fully?
Not entirely. Tools help, but human judgment is still needed for context and validation.
Why track preprocessing steps?
It ensures reproducibility and helps identify what’s improving or hurting performance.
Conclusion
Data preprocessing isn’t just a preliminary step, and it’s the bedrock of good machine learning. Clean, consistent data leads to models that are not only accurate but also trustworthy. From removing duplicates to choosing the proper encoding, each step matters. Skipping or mishandling preprocessing often leads to noisy results or misleading insights.
And as data challenges evolve, a solid grasp of theory and tools becomes even more valuable. Many hands-on learning paths today, like those found in comprehensive data science
If you’re looking to build strong, real-world data science skills, including hands-on experience with preprocessing techniques, consider exploring the Master Data Science & Machine Learning in Python program by Great Learning. It’s designed to bridge the gap between theory and practice, helping you apply these concepts confidently in real projects.