ExCyTIn-Bench is Microsoft’s newest open-source benchmarking tool designed to evaluate how well AI systems perform real-world cybersecurity investigations.1 It helps business leaders assess language models by simulating realistic cyberthreat scenarios and providing clear, actionable insights into how those tools reason through complex problems. In contrast to previous benchmarks that concentrated on threat intelligence trivia or static knowledge, this benchmark evaluates AI agents in multistep, data-rich, multistage cyberattack scenarios within a simulated security operations center (SOC) in Microsoft Azure. It incorporates 57 log tables from Microsoft Sentinel and related services to reflect the scale, noise, and complexity of real incidents and SOC operations.2
Why ExCyTIn-Bench matters for business
For chief information security officers (CISOs), IT leaders, and buyers, ExCyTIn-Bench offers a clear, objective way to assess AI capabilities for security. It’s not just about accuracy in cyberthreat reports, trivia, or toy simulations, but about how well AI can investigate, adapt, and explain its findings in the face of real-world cyberthreats. As cyberattacks grow in sophistication, tools like ExCyTIn-Bench help organizations select solutions that truly enhance detection, response, and resilience.
Microsoft uses this framework internally to strengthen its AI-powered security features and test their ability to withstand real-world cyberattacks. Our security-focused in-house models rely on feedback from ExCyTIn to uncover weaknesses in detection logic, tool capabilities, and data navigation. For broader integration, we are also collaborating with security products such as Microsoft Security Copilot, Microsoft Sentinel, and Microsoft Defender to evaluate and provide feedback on their AI features. Additionally, Microsoft Security product owners can monitor how different models perform and what they cost, allowing them to choose appropriate models for specific features.
How ExCyTIn-Bench improves upon traditional benchmarks
Unlike traditional benchmarks3,4 that rely on multiple choice questions—which are often susceptible to guesswork—ExCyTIn-Bench adopts an innovative, principled methodology for generating questions and answers from threat investigation graphs. Human analysts conceptualize threat investigations using incident graphs, specifically bipartite alert-entity graphs.5 These serve as ground truth, supporting the creation of explainable question-answer pairs grounded in authentic security data. This enables rigorous analysis of strategy quality, not just final answers. Even recent industry publications, such as CyberSOCEval,3 focus on packaging realistic SOC scenarios and evaluating how models investigate static evidence in them. ExCyTIn adopts a different approach in both design and technical implementation by positioning the agent within a controlled Azure SOC environment: where the agent queries live log tables, transitions across data sources, and plans multistep investigations.
As a result, ExCyTIn evaluates comprehensive reasoning processes, including goal decomposition, tool usage, and evidence synthesis, under constraints that simulate an analyst’s workflow. By defining rigorous ground truths and extensible frameworks, ExCyTIn-Bench enables realistic, multiturn, agent-based experimentation, collaboration, and continuous self-improvement, all reinforced by verifiable, fine-grained reward mechanisms for AI-powered cyber defense.6
ExCyTIn-Bench innovations that deliver strategic value
- Realistic security evaluation. Unlike most open-source benchmarks,3,4 ExCyTIn-Bench captures the complexity and ambiguity of actual cyber investigations. AI agents are challenged to analyze noisy, multitable security data, construct advanced queries, and uncover indicators of compromise (IoCs)—mirroring the work of human SOC analysts.
- Transparent, actionable metrics. The benchmark provides fine-grained, step-by-step reward signals for each investigative action over basic binary success and failure metrics found in current benchmarks. This transparency helps organizations understand not just what a model can do, but how it arrives at its conclusions—critical for actionability, trust, and compliance.
- Accelerating innovation. ExCyTIn-Bench is open-source and designed for collaboration. Researchers and vendors worldwide can use it to test, compare, and improve new models, driving rapid progress in automated cyber defense.
- Personalized benchmarks (coming soon). Create tailored cyberthreat investigation benchmarks specific to the threats occurring in each customer tenant.
Latest results—language models are getting smarter
Recent evaluations show that the newest models are making significant strides:
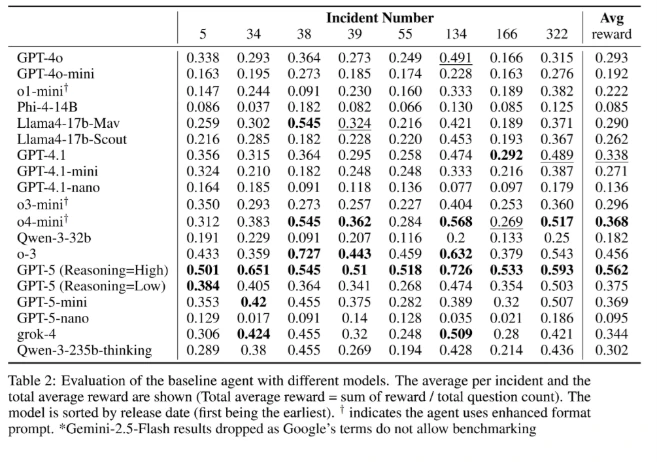
- GPT-5 (High Reasoning) leads with a 56.2% average reward, outperforming previous models and demonstrating the value of advanced reasoning for security tasks.
- Smaller models with effective chain-of-thought (CoT) reasoning—like GPT-5-mini—are now rivaling larger models, offering strong performance at lower cost.
- Explicit reasoning matters—Lower reasoning settings in GPT-5 drop performance by nearly 19%, highlighting that deep, step-by-step reasoning is essential for complex investigations.
- Open-source models are closing the gap with proprietary solutions, making high-quality security automation more accessible.
- New models are getting close to top CoT techniques (ReAct, reflection and BoN at 56.3%) but don’t surpass them, suggesting comparable reasoning during inference.
Get involved
ExCyTIn-Bench is open-source and free to access. Model developers and security teams are invited to contribute, benchmark, and share results through the official GitHub repository. For questions or partnership opportunities, reach out to the team at msecaimrbenchmarking@microsoft.com.
Thank you to the MSECAI Benchmarking team for helping this become reality.
To learn more about Microsoft Security solutions, visit our website. Bookmark the Security blog to keep up with our expert coverage on security matters. Also, follow us on LinkedIn (Microsoft Security) and X (@MSFTSecurity) for the latest news and updates on cybersecurity.
1Benchmarking LLM agents on Cyber Threat Investigation
2https://huggingface.co/datasets/anandmudgerikar/excytin-bench
3CyberSOCEval: Benchmarking LLMs Capabilities for Malware Analysis and Threat Intelligence Reasoning
4[2406.07599] CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence
5Incident or Threat Investigation graphs portray multi-stage attacks by linking alerts, events, and indicators of compromise (IoCs) into a unified view. Nodes denote alerts (e.g., suspicious file downloads) or entities (e.g., user accounts) while edges capture their relationships (e.g., a phishing email that triggers a malicious download)
6[2507.14201] ExCyTIn-Bench: Evaluating LLM agents on Cyber Threat Investigation