In this article, we’ll focus on Gated Recurrent Units (GRUs)- a more straightforward yet powerful alternative that’s gained traction for its efficiency and performance.
Whether you’re new to sequence modeling or looking to sharpen your understanding, this guide will explain how GRUs work, where they shine, and why they matter in today’s deep learning landscape.
In deep learning, not all data arrives in neat, independent chunks. Much of what we encounter: language, music, stock prices, unfolds over time, with each moment shaped by what came before. That’s where sequential data comes in, and with it, the need for models that understand context and memory.
Recurrent Neural Networks (RNNs) were built to tackle the challenge of working with sequences, making it possible for machines to follow patterns over time, like how people process language or events.
Still, traditional RNNs tend to lose track of older information, which can lead to weaker predictions. That’s why newer models like LSTMs and GRUs came into the picture, designed to better hold on to relevant details across longer sequences.
What are GRUs?
Gated Recurrent Units, or GRUs, are a type of neural network that helps computers make sense of sequences- things like sentences, time series, or even music. Unlike standard networks that treat each input separately, GRUs remember what came before, which is key when context matters.

GRUs work by using two main “gates” to manage information. The update gate decides how much of the past should be kept around, and the reset gate helps the model figure out how much of the past to forget when it sees new input.
These gates allow the model to focus on what’s important and ignore noise or irrelevant data.
As new data comes in, these gates work together to blend the old and new smartly. If something from earlier in the sequence still matters, the GRU keeps it. If it doesn’t, the GRU lets it go.
This balance helps it learn patterns across time without getting overwhelmed.
Compared to LSTMs (Long Short-Term Memory), which use three gates and a more complex memory structure, GRUs are lighter and faster. They don’t need as many parameters and are usually quicker to train.
GRUs perform just as well in many cases, especially when the dataset isn’t massive or overly complex. That makes them a solid choice for many deep learning tasks involving sequences.
Overall, GRUs offer a practical mix of power and simplicity. They’re designed to capture essential patterns in sequential data without overcomplicating things, which is a quality that makes them effective and efficient in real-world use.
GRU Equations and Functioning
A GRU cell uses a few key equations to decide what information to keep and what to discard as it moves through a sequence. GRU blends old and new information based on what the gates decide. This allows it to retain practical context over long sequences, helping the model understand dependencies that stretch across time.
GRU Diagram
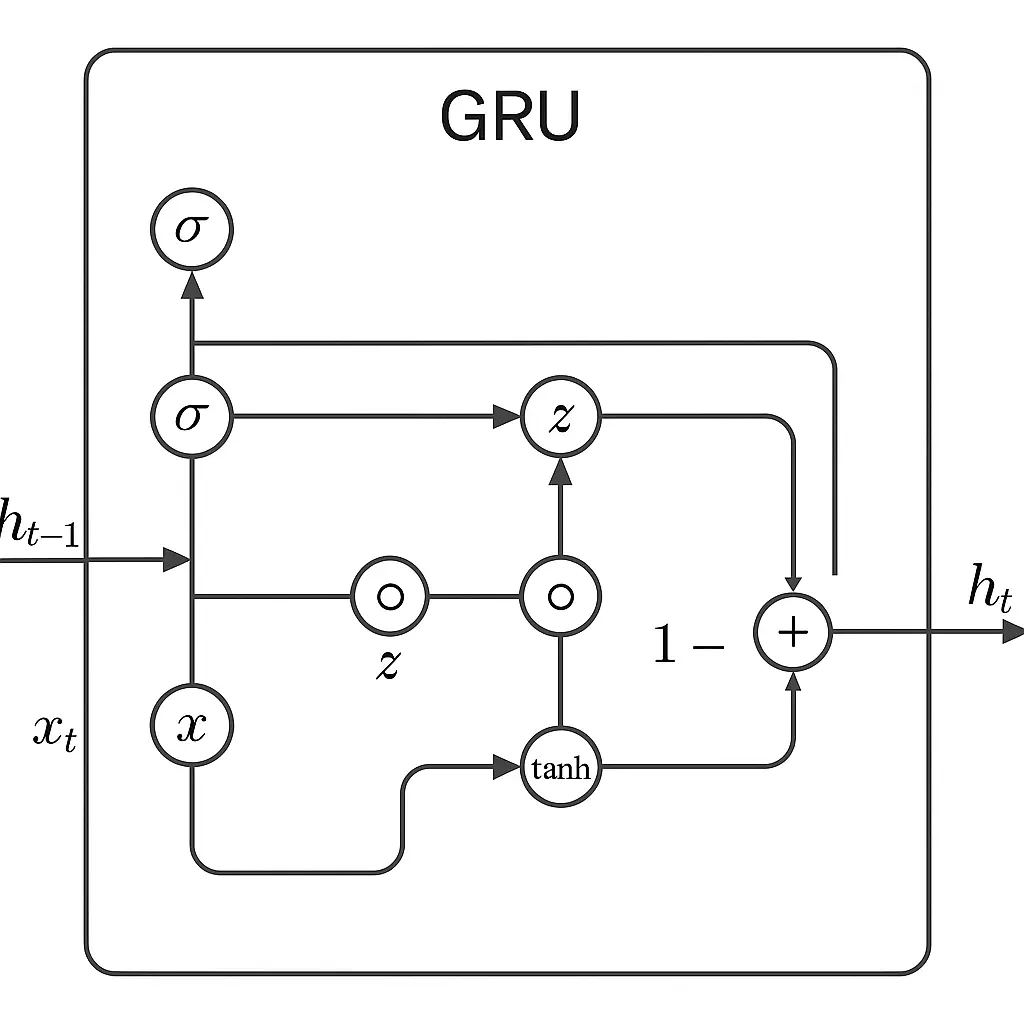
Advantages and Limitations of GRUs
Advantages
- GRUs have a reputation for being both simple and effective.
- One of their biggest strengths is how they handle memory. They’re designed to hold on to the important stuff from earlier in a sequence, which helps when working with data that unfolds over time, like language, audio, or time series.
- GRUs use fewer parameters than some of their counterparts, especially LSTMs. With fewer moving parts, they train quicker and need less data to get going. This is great when short on computing power or working with smaller datasets.
- They also tend to converge faster. That means the training process usually takes less time to reach a good level of accuracy. If you’re in a setting where fast iteration matters, this can be a real benefit.
Limitations
- In tasks where the input sequence is very long or complex, they may not perform quite as well as LSTMs. LSTMs have an extra memory unit that helps them deal with those deeper dependencies more effectively.
- GRUs also struggle with very long sequences. While they’re better than simple RNNs, they can still lose track of information earlier in the input. That can be an issue if your data has dependencies spread far apart, like the beginning and end of a long paragraph.
So, while GRUs hit a nice balance for many jobs, they’re not a universal fix. They shine in lightweight, efficient setups, but might fall short when the task demands more memory or nuance.
Applications of GRUs in Real-World Scenarios
Gated Recurrent Units (GRUs) are being widely used in several real-world applications due to their ability to process sequential data.
- In natural language processing (NLP), GRUs help with tasks like machine translation and sentiment analysis.
- These capabilities are especially relevant in practical NLP projects like chatbots, text classification, or language generation, where the ability to understand and respond to sequences meaningfully plays a central role.
- In time series forecasting, GRUs are especially useful for predicting trends. Think stock prices, weather updates, or any data that moves in a timeline
- GRUs can pick up on the patterns and help make smart guesses about what’s coming next.
- They’re designed to hang on to just the right amount of past information without getting bogged down, which helps avoid common training issues.
- In voice recognition, GRUs help turn spoken words into written ones. Since they handle sequences well, they can adjust to different speaking styles and accents, making the output more reliable.
- In the medical world, GRUs are being used to spot unusual patterns in patient data, like detecting irregular heartbeats or predicting health risks. They can sift through time-based records and highlight things that doctors might not catch right away.
GRUs and LSTMs are designed to handle sequential data by overcoming issues like vanishing gradients, but they each have their strengths depending on the situation.
When to Choose GRUs Over LSTMs or Other Models
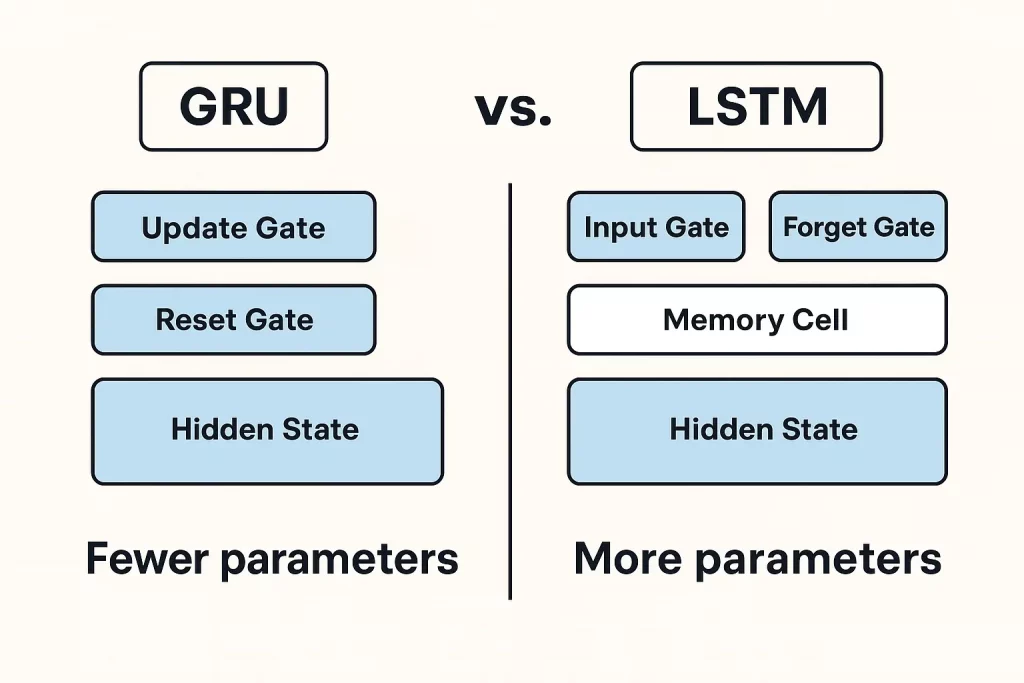
Both GRUs and LSTMs are recurrent neural networks used for the processing of sequences, and are distinguished from each other by both complexity and computational metrics.
Their simplicity, that is, the fewer parameters, makes GRUs train faster and use less computational power. They are therefore widely applied in use cases where speed overshadows handling large, complex memories, e.g., online/live analytics.
They are routinely used in applications that demand fast processing, such as live speech recognition or on-the-fly forecasting, where quick operation and not a cumbersome analysis of data is essential.
On the contrary, LSTMs support the applications that can be highly dependent upon fine-grained memory control, e.g. machine translation or sentiment analysis. There are input, forget, and output gates present in LSTMs that increase their capacity to process long-term dependencies efficiently.
Although requiring more analysis capacity, LSTMs are generally preferred for addressing those tasks that involve extensive sequences and complicated dependencies, with LSTMs being expert at such memory processing.
Overall, GRUs perform best in situations where sequence dependencies are moderate and speed is an issue, while LSTMs are best for applications requiring detailed memory and complex long-term dependencies, though with an increase in computational demands.
Future of GRU in Deep Learning
GRUs continue to evolve as lightweight, efficient components in modern deep learning pipelines. One major trend is their integration with Transformer-based architectures, where
GRUs are used to encode local temporal patterns or serve as efficient sequence modules in hybrid models, especially in speech and time series tasks.
GRU + Attention is another growing paradigm. By combining GRUs with attention mechanisms, models gain both sequential memory and the ability to focus on important inputs.
These hybrids are widely used in neural machine translation, time series forecasting, and anomaly detection.
On the deployment front, GRUs are ideal for edge devices and mobile platforms due to their compact structure and fast inference. They’re already being used in applications like real-time speech recognition, wearable health monitoring, and IoT analytics.
GRUs are also more amenable to quantization and pruning, making them a solid choice for TinyML and embedded AI.
While GRUs may not replace Transformers in large-scale NLP, they remain relevant in settings that demand low latency, fewer parameters, and on-device intelligence.
Conclusion
GRUs offer a practical mix of speed and efficiency, making them useful for tasks like speech recognition and time series prediction, especially when resources are tight.
LSTMs, while heavier, handle long-term patterns better and suit more complex problems. Transformers are pushing boundaries in many areas but come with higher computational costs. Each model has its strengths depending on the task.
Staying updated on research and experimenting with different approaches, like combining RNNs and attention mechanisms can help find the right fit. Structured programs that blend theory with real-world data science applications can provide both clarity and direction.
Great Learning’s PG Program in AI & Machine Learning is one such avenue that can strengthen your grasp of deep learning and its role in sequence modeling.