How to Diagnose Why Your Classification Model Fails
Image by Editor | ChatGPT
Introduction
In classification models, failure occurs when the model assigns the wrong class to a new data observation; that is, when its classification accuracy is not high enough over a certain number of predictions. It also manifests when a trained classifier fails to generalize well to new data that differs from the examples it was trained on. While model failure typically presents itself in several forms, including the aforementioned ones, the root causes can sometimes be more diverse and subtle.
This article explores some common reasons why classification models may underperform and outlines how to detect, diagnose, and mitigate these issues.
Diagnostic Points for a Classification Model
Let’s explore some common causes for failure in classification models, outlining each one and providing practical tips for its diagnosis.
1. Analyzing Performance Metrics and a Confusion Matrix
You just trained a model, evaluated it on a set of test data using a single performance metric like accuracy, and found that the resulting percentage of correct predictions is not high enough. While this is the most obvious sign that your classifier might not be working at its best, relying solely on accuracy can be misleading, especially when diagnosing the root cause of a model’s poor performance. This is even more true for an imbalanced dataset, as we will explain shortly.
Key actions to diagnose your model by analyzing evaluation metrics include:
- Use and understand a combination of classification metrics — mainly precision, recall, and the F1-score, which combines the two. For a more visual outline of the model’s performance, ROC-AUC is another metric to consider. Depending on the nature of your problem and the cost of different types of classification errors — such as false positives versus false negatives — you would prioritize one metric over another.
- The confusion matrix is useful to view the classification performance by class. Likewise, Python’s scikit-learn library provides a function,
classification_report(), which also calculates precision, recall, and F1-scores per class automatically, providing a glance at which classes in your dataset have better performance than others that may be more ‘problematic’ to classify correctly. - Possible remedies to mitigate performance problems include adjusting classification thresholds, improving the quality of the training data used to build the model, or fine-tuning the model hyperparameter settings.
2. Checking for Class Imbalance
Some real-world datasets, like those describing credit card transactions or rare disease diagnosis data, naturally exhibit a phenomenon known as class imbalance: a vast majority of the data belongs to a specific class, with the remaining minority belonging to other classes. In statistical terms, there is a highly skewed class distribution in the data, which can lead a trained classifier to overly favor the majority class in its predictions, making it barely able to recognize the comparatively infrequent cases associated with minority classes.
To diagnose this problem, first examine your class frequency distribution to ascertain whether or not there is class imbalance, and carefully analyze per-class performance metrics as discussed earlier.
More specific remedies include the use of oversampling techniques like SMOTE to address imbalances, undersampling, class weighting to assign greater importance to misclassifications related to minority classes, or collecting more data for those classes. Precision-recall curves are another useful visual aid to analyze the performance of classifiers for imbalanced data.
Relying solely on a classification model’s accuracy can be misleading, especially when diagnosing the root cause of its poor performance.
3. Inspecting Data Quality and Feature Relevance
Poor data quality is frequently a major cause of underperforming machine learning models, and classifiers are no exception. Therefore, an important diagnostic point is to analyze the quality of the data that has been fed to the model, both for training and testing.
Using approaches like exploratory data analysis (EDA), check for missing values and how frequently they appear. Identify features that might be irrelevant and could perhaps be removed—using feature importance-based tools for model interpretability can be helpful here. You should also inspect for incorrectly assigned labels, scaling issues with numerical features, or data that simply doesn’t match the model type or deployment environment.
In sum, make sure both feature engineering and data cleaning and validation processes are firmly aligned with the prediction task at hand.
4. Overfitting, Underfitting, and Calibration Analysis
A key performance issue, also discussed in the recent article about diagnosing regression models, is overfitting and underfitting. Underfitting occurs when the model fits the training data poorly, while overfitting occurs when it fits the training data too well. Both can cause serious performance issues on validation and test data, rendering the model unsuitable for real-world deployment. Therefore, addressing these issues is a top priority. In addition, calibration issues might also occur when model probabilities of classifying data into different classes do not match actual ground-truth likelihoods.
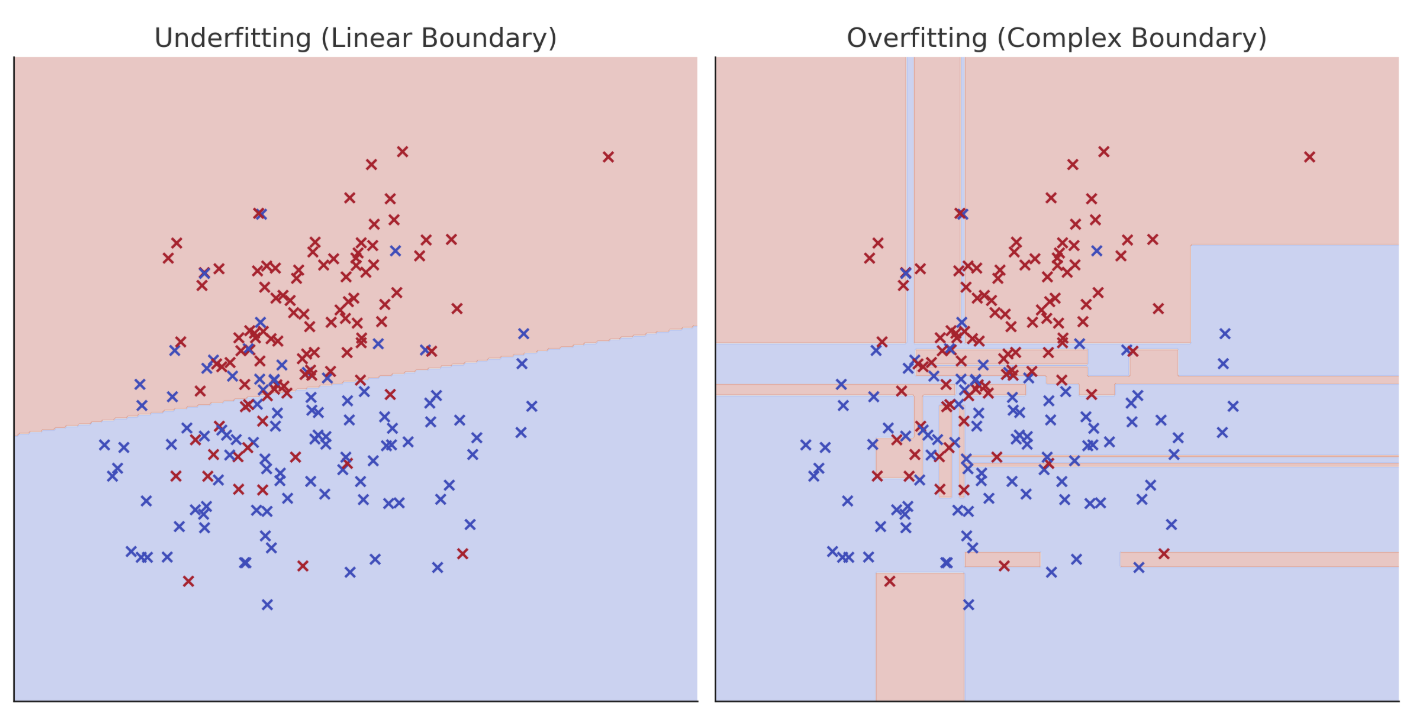
Underfitting and overfitting in classification models
To diagnose and deal with overfitting and underfitting, visualize training versus validation curves (or learning curves for short), as is common with neural network classifiers trained using TensorFlow. Reliability diagrams can help recalibrate probabilities and navigate potential calibration issues, and other strategies like regularization, or adjusting the complexity of models like decision trees, support vector machines, and neural networks, can also help address overfitting.
5. Detecting and Handling Concept Drift
Suppose your model has been finally deployed because a proper diagnosis helped you get to a point where the four issues discussed above no longer prevail. Once deployed and in production, another important problem must be monitored, diagnosed, and handled over time: data drift—in other words, changes in the statistical properties of your input data distribution compared to the training data. One particular case of data drift is concept drift, in which the relationship between features and class labels evolves over time due to changes in the underlying application scenario.
To diagnose concept drift, establish a solid scheme for monitoring feature distribution statistics between training and incoming production data, issuing alerts when the distribution in production data differs significantly from that of the data used to train a model. This is a reliable sign that your model might need to be retrained on fresh, updated data. Also, perform periodic validations of the performance of recently labeled data samples. Well-designed drift detection systems and building adaptive learning pipelines are helpful to manage this problem in production classifiers.
Final Thoughts
This article examined several common reasons why machine learning models for classification may fail to perform well, from data quality issues to class imbalance and data drift once in production. The discussion placed particular focus on ways to diagnose these diverse root causes of underperforming classifiers, using an explanatory and evidence-based approach.